CS5322 Database Security
Pinned resources
- Drive repository: Google Drive
- Report: Application 1
- Collaboration document: Application 1
- SoC resource documentation: https://dochub.comp.nus.edu.sg/start
- Create SoC account: https://mysoc.nus.edu.sg/~newacct
-
- Microsoft Windows: Forticlient via Microsoft Store, then connect to
webvpn.comp.nus.edu.sg. Desktop client bugging out for me. - SoC VPN guide: https://dochub.comp.nus.edu.sg/cf/guides/network/vpn?s[]=vpn
Finals
The actual finals (AY2022/23) is very similar to that of the only available past year finals paper in NUS Libraries. Questions posed for this finals were:
- Summarize key ideas from two of the 12 student presentations, in one short paragraph each.
- Effect of queries and updates on label-based security (with polyinstantiation)
- Determine if two watermarking schemes are valid, one of them is (++++, -+++, --++, ---+, ----)
- Random perturbation with two independently perturbed answers submitted per user: calculate the true fraction, and posterior belief
- Demonstrate an example of inference attack using only the AVG query conditioned on names, given: (1) query set size >= 3, or (2) denial of queries if query reveals information.
Overall not a bad module, with a lecturer that explained concepts in a step-wise manner and effectively.
Week 9-13
No more lecture content, the rest is module-related projects and assignments.
- Week 9: Database demonstrations for Project 1
- Week 10: Group presentations - enclave-based databases
- Week 11: Group presentations - enclave-based key-value stores
- Week 12: Group presentations - ?
- Week 13: Database demonstrations for Project 2
Week 8
Watermarking relational data
R. Agrawal, P. J. Hass, J. Kiernan (AHK), “Watermarking Relational Data: Framework, Algorithms and Analysis”, VLDB Journal, 2003
We want to be able to attribute database leaks to a specific culprit, by adding user-specific watermarks on user received records. This should be applicable to situations even when the user leaks partial records. One approach is to add false information into the database which should be difficult to detect, and should not affect the utility of the data.
Some assumptions on database for AHK approach to work:
- Table T for watermarking has a number of numeric attributes and a primary key P (primary key used for identification of watermarks)
- Numeric attributes can be perturbed by modifying some least-significant bits used for watermarking (utility of data is minimally affected)
- Detection of watermarks does not require access to T (i.e. no requirements to retain old records for watermark checking)
AHK strategy uses primary key P to determine (1) whether tuple and some of its attributes should be watermarked, and (2) how many LSBs to change. This is achieved by using a cryptographic pseudo-random number generator (CSPRNG). Algorithm:
- Salt the primary key P by prepending secret key K, then use as seed to the PRNG G.
- Get a sequence of four random numbers A, B, C, D:
- Given fraction of tuples to be watermarked f, watermark if
A mod 1/f = 0 - Given number of attributes in T d, watermark
B mod d = i-th attribute - Given user-defined number of LSBs to watermark e, watermark
C mod e = j-th LSB - Set the j-th LSB
D mod 2
This is customized by using a different K for each user. Watermark detection is achieved by checking the number of times the calculated watermarked bit coincides in the leaked data. On average, only 50% of bits will match for any user (random), while a match percentage ≫50% indicates high probability of leak by that user (≪50% indicates user likely manipulated the bits). This is a binomial distribution - can use some p-value as the detection cutoff.
Exercise on crafting detection algorithm.


Answers: For (2), table T must be accessible.


AHK watermarks are easy to circumvent via collusion between two users, since watermarked bits are unlikely to coincide for each set of data. Using a majority vote with three users, watermarking can be corrected for.
D. Boneh and J. Shaw. “Collusion-Secure Fingerprinting for Digital Data”. IEEE Transaction on Information Theory, 1998.
Collusion can be guarded against by using a different watermark partitioning strategy, and correlating all the watermark bits between users, analogous to a (k,n)-secret sharing scheme. One approach is to choose a universal secret key K to apply the AHK algorithm, then assign different partitions of the table for each user with either the original watermarked bits, or with flipped watermark bits.

Watermarks can be detected and partially mitigated by performing a random bit flip at watermark locations (known by users sharing anti-correlated bits). Common partitions shared by the users however cannot be detected.
In the example above, matched D2+ and D3+ data indicates collusion (u1, u2), while matched D3+ data indicates collusion (u1, u3). It is important for the partitioning to be unknown to users, otherwise a collusion (u1, u3) can allow them to generate the dataset obtainable by u2. A watermarking partition scheme is considered good if:
- It prevents innocent users from being implicated when the colluding users either apply a majority or minority rule to their set of data (recall that users are unable to apply either rule selectively based on partitioning)
- At least one colluding user can be identified (and by extension prevent collusion)
Note that categorical data can also be watermarked by randomly changing the value, but this presents difficulties in maintaining data validity, e.g. male patient having breast cancer.
Exercise to determine if watermarking scheme is good



Answers: Not ok (note blue is D3+, u3 = majority(u1,u2,u4)), Ok, Not Ok
Explanation for OK scheme:
- Any 3-user collusion cannot frame the last person
- The following decomposition can occur:
- D1 compromised -> u1 will be identified.
- If u1 not colluding, then D4 compromised -> u2 identified.
- If u1, u2 not colluding, then (D2,D3) compromised -> u3, u4 identified.
Week 7
Query authentication and integrity
There is always a risk that the service provider does not respond correctly to user queries, e.g. malicious dropping of tuples, subset of queries due to lack of query processing resources, replay results from outdated database. Idea is to have database return both the result as well as a proof of correctness - attempted by Amazon and Microsoft.
This can be achieved via PKI: messages that can be decrypted by the public key must have been encrypted by the data owner's encrypting private key. This enables authentication of messages (but not integrity, yet). Note that this by itself is insufficient - service providers can always replay authenticated by outdated messages to new queries.
Merkel tree
This was invented by Ralph Merkle in 1979 - a tree structure that allows efficient verification of its contents Using a Merkel tree, no tuples need to be encrypted + support for range queries.
The tree is constructed by first sorting the column to be queried, then performing a hash on each tuple. A binary tree is built where each node is the hashed concatenation of its two children. The data owner will provide the hash at the root node for proof of integrity of the whole table.

In the example above, when the user makes a query for Salary = 3.5k, the table will return h(v1), t3, t4, and h(v6). The user can verify this by computing:
$$$$ h(v_1)\;||\;h(h(t_3)||h(t_4)) = v_5 $$$$ $$$$ h(h(v_5)||h(v_6)) = h(v_7) $$$$
The general algorithm for a range is simply:
- Collect all contiguous tuples with minimum and maximum outside the range.
- For all left branch on the path to root for minimum, collect left hash.
- For all right branch on path to root for maximum, collect right hash.
Exercise in Merkle tree queries

Answer: h(v1), t3, t4, t5, h(t6), h(v4)
When tuples are updated, owner can reconstruct the tree and send out the updated root hash with timestamp. Alternatively, can use an update-friendly tree structure, e.g. red-black tree - subtrees can be independently signed.
For multi-dimensional queries, e.g. SELECT * FROM Employee WHERE Age > 30 AND Salary > 10000, can use multi-dimensional indices such as an R-tree using nearest-neighbor grouping instead, example below with bounding cuboids to form each node in data of dimensionality 3. In the same spirit of Merkle tree, we return hashes of all rectangles that do not intersect with the queries, and all the other data points otherwise.

Week 6
Encrypted databases
To minimize risks of data leaks, databases can be encrypted by the data owners before sending it to the service provider. The challenge of encrypting database at rest involves answering database queries without knowledge of the database contents. Two possible solutions:
- Homomorphic encryption:
- Encryption schemes that allow computation on encrypted data, e.g. RSA is multiplicative homomorphic.
- Need to find a fully homomorphic scheme which supports both multiplication and addition as well.
- The earliest fully homomorphic encryption scheme was developed by Craig Gentry in 2009, but is extremely slow and space-consuming (order of hours/bit). Currently still far from practical.
- Hardware-assisted security:
- Using a trusted secure processor on service provider's machines.
- Secure processor decrypts encrypted data from machines and user queries, computes the result, then sends the result encrypted to user.
Historical examples of secure processors:
- IBM 4764
- Tamper-responsive: physical accesses to data will be detected and data destroyed
- Intel Software Guard Extensions (SGX):
- Uses a set of CPU instruction codes that allows a user to create an enclave (secure region) in memory that is encrypted
- Decryption and computation is shielded from remote machine
- Requires communication with Intel for authentication
- Small cache size of 128 MB
Note that both methods are still vulnerable to leakage through access patterns by observing frequency and order of data accesses - this can be mitigated by oblivious processing which masks the sequence of data as well.
HILM
H. Hacigümüs, B. R. Iyer, C. Li, S. Mehrotra. Executing SQL over encrypted data in the database-service-provider model. SIGMOD 2002: 216-227
The HILM approach proposes to split the query processing task between the user and the service provider, such that the service provider alone cannot perform the full decryption. The architecture of such a setup is as follows:

The idea is that the service provider processes groups of row-encrypted tuples (using any form of encryption technique) identified by a set of indices, instead of the original rows themselves.
These indices are generated by the data owner by defining a mapping function $$ Map_{cond} $$ for each column, that maps different partitions of values each into a randomly chosen index. This mapping to known to both user and client (but not the server!) during query processing.
$$$$ R = \langle{}A,B,C\rangle{}\;\Leftrightarrow\;R^S = \langle{}E(R), A_{id},B_{id},C_{id}\rangle{},\qquad X_{id} = Map_{R.X}(X) $$$$


This is workable in its basic form: client retrieves the whole database and performs its own decryption (although losing any benefit of row-grouping in the first place). We can further optimize this by offloading the SELECT $$ \sigma{} $$ and JOIN $$ \bowtie{} $$ operators to the server for query processing as well.
SELECT is straightforward: translate the SELECT query into an equality-based SELECT query over the indices, e.g.
$$$$ \sigma{}_{(S>100)} \rightarrow \sigma{}^S_{(S_{id} = 3) \cup{} (S_{id} = 7)} $$$$


JOIN over columns from two different tables requires enumerating all possible pairwise combinations of ids for each table, since the mapping condition can be different for the same set of column values, e.g.
$$$$ R\bowtie{}_{(R.N = T.N)}T \rightarrow R^S\bowtie{}^S_{( (R^S.N_{id} = 4)\cap{}(T^S.N_{id} = 5) )\cup{}(\cdots{})}T^S $$$$


Further optimizations can follow:
- Since the client still needs to perform JOIN on the decrypted rows, the server only needs to send the "joinable" partitions to clients without needing to perform server-side JOIN.
- Individual attributes instead of the entire tuple can be encrypted instead for more compact responses.
- Attributes that are frequently used for aggregation can employ partial homomorphic encryptions to offload this aggregation to the service provider, e.g. mean of salaries.
Is implementing Update possible in HILM?
Several issues still remain:
- Client needs to perform query processing as well
- Partitioning of attributes does not have a formal security guarantee
- Service provider might also be able to infer rows sharing same partition index are more similar
CryptDB
R. A. Popa, C. M. S. Redfield, N. Zeldovich, H. Balakrishnan. “CryptDB: Protecting Confidentiality with Encrypted Query Processing”. SOSP 2011.
Goal of CryptDB is to support standard SQL queries on encrypted data, which are processed entirely by the DB server. The client itself holds schema and master key, and server can use the same DB management system - CryptDB provides a decryption layer and holds the public keys.

Instead of partitioning, each tuple is individually encrypted using known encryption schemes. The encryption scheme used for query processing is chosen based on the type of operation the user wishes to support. Some possible characteristics:
- Deterministic for equality search: $$ P_1 = P_2 \Leftrightarrow C_1 = C_2 $$
- Order-preserving for inequality search: $$ P_1 < P_2 \Leftrightarrow C_1 < C_2 $$
- Substring-checking for wildcard/keyword search: Token (translated from keyword) and some filter function $$ F $$ for checking keyword existence is sent to the server
- Partial homomorphic for addition/multiplication
- Randomized if no search is required
The choice of encryption scheme yields different security guarantees. In CryptDB, a lower (and well-understood) security guarantee is accepted in favor of supporting query processing requested by the user.

To support different encryption schemes, rather than having multiple copies of the same database each with different encryption schemes, CryptDB encrypts each tuple multiple times, typically in order of increasing security. This set of encryption layers is denoted as an onion. Users provide the private key for DB to access the inner layers only on query processing request (note that the last layer is never decrypted).
Multiple onions can also exist, e.g. if SUM needs to be supported, then both deterministic encryption and additive homomorphic encryption needs to be supported, but HOM must be applied to the original data and also destroys any ordering.

Equi-join requires a second look at its implementation details. If the same columns across different tables are deterministically encrypted with the same key, then the service provider will know how to join the tables without the user issuing a join operation (remember that we want to minimize unnecessary information leakage). The strategy employed is:
- Two unique keys per column $$ C_i $$ per table:
- One key deterministically encrypts the column as usual
- The other key is used to generate tags in the column (essentially hashing)
- Each attribute is identified by the concatenation $$ \text{Tag}_{k1}(C_1) \Vert{} {\text{DET}}_{k2}(C_1) $$
- When user issues a join operation, the tags are adjusted to match across the columns, so that the server knows how to perform the join.
- Achieved by using ECC: the pseudorandom function with key $$ \text{PRF}, k0 $$, and public parameter $$ P $$ are the same, but with different secret keys.
- Plaintext are still protected
$$$$ \text{Tag}_{k1}(C_1) = P^{k1*PRF(C_1,k0)}, \qquad \text{Tag}_{k2}(C_1) = [\text{Tag}_{k1}(C_1)]^{k2/k1} $$$$
Some issues still remain:
- Not all operations can be performed:
WHERE T1.a + T1.b > T2.crequires OPE on top of additive HOMSUM(100*a + 2*b)requires full HOM
- Some level of overhead in decryption
Industry is increasingly adopting secure modules like Intel SGX in today's context.
Week 5
Inference analysis
In evaluating the degree of protection provided by each data perturbation method, we utilize Bayesian inference. The adversary has some prior belief $$ Pr[H]$$ about hypothesis H, and after observing the perturbed data, the adversary has a posterior belief $$ Pr[H|D] $$. We want the adversary to learn as little as possible, i.e. minimize the difference between $$ Pr[H|D] $$ and $$ Pr[H]$$.
$$$$ Pr[H|D] = \frac{Pr[H\wedge{}D]}{Pr[D]} = \frac{Pr[D|H] \cdot{} Pr[H]}{Pr[D]} $$$$
Exercise in calculating posterior belief for l-diversity


Generalized case:

Answers: 1/2, 2/3, p1p4/(p1p4 + p2p3)
Quantifying this probability difference for l-diversity requires an accurate modelling of background information of the adversary, otherwise it can be arbitrarily large when no assumptions about the prior probabilities are made.
Exercise in calculating posterior belief for inference analysis


Generalized case:

Answers: 9/13 (+15%), 9/14 (-14%), upper bound (1+p)/(1-p) lower bound (1-p)/(1+p)
For randomized responses, we can show that the change in adversary's belief is no more than a factor of $$ \frac{1+p}{1-p} $$, regardless of the adversary's prior belief. This is much stronger guarantee than l-diversity.
Week 4
Statistical database
Access control enforces authorization for direct accesses, but does not necessarily prevent inference of sensitive information. Identifiers that provide supplementary information that do not directly identify someone are termed quasi-identifiers.
Quasi-identifiers can provide identity information by cross-referencing
During mid-1990s, the Massachusetts Group Insurance Commission (MGIC) released medical records which were anonymized by removing the name column. A PhD student identified the medical records of the Massachusetts governor by cross-referencing with another database which share the same columns {date of birth, gender, zip code}. [Golle06] showed that 63% of Americans can be uniquely identified by this same set.
User' behaviour traces can reveal identities even without quasi-identifiers
In 2006, AOL released an anonymized log of their search engine for research, with each row containing only an ID (all identifiers and quasi-identifiers removed). New York Times was able to identify a user by their queries for businesses and services in the township + queries for family members.
In that same year, Netflix also released a set of movie ratings made by its users for a competition. Researchers matched Netflix users to IMDB users by cross-referencing the dates of reviews made by users on IMDB, showing that 99% of users can be identified with 8 ratings + dates.
Aggregate data can also reveal identities
The National Institutes of Health (NIH) used to publish aggregate information from genome wide association studies (GWAS), which takes DNA from a test population of 1,000 individuals with a common disease and averages the frequency of 100,000 DNA markers. [Homer08] demonstrated that it is possible to infer whether an individual is in the test population, using statistics from a reference population as background information.
We can alleviate inferences of sensitive information by using statistical databases, which do not provide access to detailed records, but instead provide statistics of records (e.g. SUM, MEAN, COUNT, MAX) with additional measures for inference control:
- Query auditing: Keep track of user queries to see if queries reveal sensitive information. Auditing can be performed offline or online (the latter more difficult due to efficiency requirements)
- Data perturbation: Modify original data so that queries on modified data does not reveal too much sensitive information (e.g. US Census data)
- Output perturbation: Inject noise into each query answer (e.g. a range of possible values)
Query auditing
Of all the query auditing techniques covered below, not all of them are intrinsically secure against attacks.
Query set size and overlap control
Selectivity is defined as the number of rows that satisfy the query predicate. Since queries with small selectivities are more likely to reveal sensitive information, a simple idea is to impose selectivity constraints on each query (Query Set Size Control), e.g. at least K. This alone however is insufficient, consider the following case:
# Not allowed Query 1 (selectivity 1) : SELECT Grade FROM Grades WHERE Name == 'Alice' # Allowed, and the combination yields the same result as Query 1 Query 2 (selectivity n) : SELECT SUM(Grade) FROM Grades Query 3 (selectivity n-1): SELECT SUM(Grade) FROM Grades WHERE Name <> 'Alice'
This leads to the idea that queries should not overlap too much as well, i.e. the pairwise queries in a query set should overlap on at most r tuples (Query Set Overlap Control). This however is still insufficient,

This means that query set overlap control techniques do not work perfectly, especially if attacker exploits more query correlations than just overlaps.
Other auditing techniques
If only SUM queries are allowed, then we can express queries as a linear system $$ Q = WX $$ and check if the linear system can solve for any value of $$ x_k $$.
This however cannot be easily extended to non-linear queries, e.g. MAX. Denial of queries will not solve this problem either. If a denial is due to the result revealing a unique solution, then the attacker can consider (possibly unique) solutions that will lead to a denial, hence revealing information.
Some exercises on query auditing


Answers:


Data perturbation
In practice, k-anonymity, data swapping, synthetic data generation, and random perturbation is more commonly used.
k-anonymity
The idea of data perturbation is to make groups of tuples more indistinguishable, so that individual tuples cannot be identified. This process is called generalization.

Generalization is quantified by the metric $$k$$-anonymous, where each tuple is indistinguishable from at least k-1 other tuples on non-sensitive attributes (quasi-identifiers). This however does not impose constraints on sensitive attributes within each tuple group, e.g. if all tuples share the same value for a sensitive column.
In practice, k-anonymity is still used often since it is easy to understand.
l-diversity
We improve on k-anonymity by considering the spread of sensitive values within each group, which we quantify by $$l$$-diversity, where each indistinguishable group of tuples has at least l well-represented sensitive values.
Well-represented is application-dependent, e.g. if we define well-respresented grades as grades that differ pairwise by at least 20, then $$T^*$$ in the generalized table above is not 2-diverse.
l-diversity cannot account for background knowledge that can add further constraints to isolate sensitive values, e.g. men are less likely to have breast cancer. If the l-diversity generalization algorithm is known, then the adversary can also make inferences on the original data given the final generalized table and l-diversity condition + algorithm. Designing a generalization algorithm that maintains Kerckhoff's principle (cryptosystem should be secure even if everything, except the private key, is public knowledge) is difficult.
Example of inference based on l-diversity algorithm

Data swapping
In data swapping, some data is swapped among tuples to make them non-identifying. There is no formal privacy guarantee for data swapping. This approach is used for the US Census.
Synthetic data generation
A statistical model is generated from the original database, which in turn is sampled to generate synthetic data for the queried table. In this case, it is possible to provide some formal privacy guarantees by injecting noise into the statistical model. This approach is also used for the US Census.
Random perturbation
This approach is used by Google Chrome and Apple iOS to collect data from users, e.g. operating system, words, emojis used. During data aggregation, each user adds noise to their responses before giving it to the server.
[Warner65] provided a model of randomized responses, where the responses are true answers with probability $$p$$ and otherwise random with probability $$1-p$$. This preserves privacy for individual tuples while yielding high-level statistical information.
Example of statistics from binary question

Given probability $$p = 20\%$$, and the statistics from 10k people yield 5.5k yes and 4.5k no, with randomized responses yielding $$ 50\%$$ yes and $$50\%$$ no. Average noise is 4k for each outcome, so yes for roughly 75% of answers.
Other techniques for noisy perturbation include adding a zero-mean random noise to numerical data, such that the noise will zero out upon aggregation.
Week 3
Oracle Label Security (OLS)
Oracle's implementation of multilevel security (MLS), which only has one label per tuple, so no polyinstantiation. Access is controlled by labels of both tuple and user session (MAC), as well as policy privileges of the user session (FGAC).
Each data label consists of three components:
| Component | Multiplicity | Condition | Remark |
|---|---|---|---|
| Level | Single | Minimum user level | e.g. Confidential (10) |
| Compartments | Multiple | User access to all | Categories |
| Groups | Multiple | User access to any or any ancestor | Hierarchy-based |
User labels have a little more components:
- Default, maximum & minimum level: for access authorization
- Row level: default level for writing rows
- Read & write compartments
- Read & write groups
On top of the usual compartment and group conditions:
- Read access to tuple is granted only if tuple level ≤ user's level
- Write access to tuple is granted only if minimum level ≤ tuple level ≤ session level
Policy creation and enforcement takes the following steps. First a policy is created.
SA_SYSDBA.CREATE_POLCY(
policy_name => 'emp_ols_pol',
column_name => 'ols_col', # stores data labels
default_options => 'READ_CONTROL, WRITE_CONTROL'); # others available
Once the labels themselves are also created, the policy can be attached to a table (or entire schema) and labels added to tuples and users.
Special privileges can also be granted by OLS to bypass policies, e.g.
- READ: Read all data, useful for sysadmins/auditors
- FULL: Read and write all data
- WRITEUP: Raise the level of a tuple up to user maximum level
- WRITEDOWN: Lower the level of a tuple down to user minimum level
- WRITEACROSS: Modify compartments and groups
Role-based Access Control
Idea is that users taking up the same roles tend to have the same access rights, so rights management can be performed on groups of users instead.
- Roles are assigned permissions, and users roles
- Users activating their roles is considered a session
RBAC models specify the relationships between users, roles, permissions and sessions.
RBAC0
Ravi S. Sandhu, Edward J. Coyne, Hal L. Feinstein, Charles E. Youman: Role-Based Access Control Models. IEEE Computer 29(2): 38-47 (1996)

$$ \text{RBAC}_0 $$ is the most basic model, with:
- Permission assignment (PA): Many-to-many (to roles)
- User assignment (UA): Many-to-many (to roles)
- Session-User (SU): Many-to-one
- Session-Role (SR): Many-to-many (permissions are union of all roles)
Permissions are set by sysadmins who possess administrative permissions. Sessions on the other hand are set by users, who can activate any subset of roles and change roles within the session.
RBAC1

In RBAC1, role hierarchies are added into RBAC0, which is a partial order relationship over the roles (i.e. reflexive, transitive, anti-symmetric) where rights given to lower level roles are inherited by higher level role.

Private roles can be added to allow roles to keep certain things private, e.g. work-in-progress. These private roles can also form a sub-hierarchy.
RBAC2

In RBAC2, constraints are added into RBAC0 to enforce organization-wide policies, e.g.
- Mutually disjoint roles for separation of duties (e.g. purchasing manager and auditor)
- Cardinality to restrict maximum number of roles per user
- Role dependencies (e.g. users can be assigned role A only if previously assigned role B)
Since constraints are managed on user-basis rather than roles, the system needs to manage user ids carefully, e.g. avoid duplicate ids.
RBAC3
RBAC3 combines both RBAC1 and RBAC2 to incorporate both role hierarchies and constraints. Issues can arise from managing separation-of-duty (SoD) constraints and hierarchies together, e.g.
- A project manager has access rights of a programmer and tester
- A user cannot be a programmer and tester simultaneously
The system thus needs to specify whether roles like these are allowed given SoD constraints.
NIST RBAC
David F. Ferraiolo, Ravi S. Sandhu, Serban I. Gavrila, D. Richard Kuhn, Ramaswamy Chandramouli: Proposed NIST standard for role-based access control. ACM Trans. Inf. Syst. Secur. 4(3): 224-274 (2001)
Similar to RBAC3 but explicitly defines mappings from permissions to objects and operations, using two types of SoD constraints: static and dynamic.
Static SoD (SSoD) contains two components $$ (RS, n) $$, where RS is a set of roles and n specifies the number of roles a user cannot take from RS simultaneously. Dynamic SoD (DSoD) additionally requires users activate no more than n roles from RS in the same session.
Exercise on compatibility between SSoD and DSoD





Answers: -.
RBAC in Oracle Database
# Creates role CREATE ROLE BruceWayne IDENTIFIED BY IAmBatman # Grant role rights on table T GRANT insert, update on T TO BruceWayne # Revoke insert rights on T REVOKE insert on T FROM BruceWayne # Grant role to user GRANT BruceWayne to Cedric # User activates role Cedric: SET ROLE BruceWayne IDENTIFIED BY IAmBatman # Revoke role from user REVOKE BruceWayne FROM Cedric # Remove role DROP ROLE BruceWayne
Separation of duties are not implemented in PL/SQL (VPD), but is available in Oracle Database Vault instead.
Week 2
Fine Grained Access Control
Consider the scenario where users can see own statistics in database, and superusers can see all statistics. Fine-grained access control can be implemented in different manners:
- Views as part of standard SQL (too many views to individually manage)
- Another application as abstraction layer between database and users (application code can see the whole table)
- Parameterized views instantiated at run-time (different views need to be queried for users vs superusers)
- View replacement by database itself, which is authorization-transparent - approach used by Oracle's Virtual Private Database (VPD)
- Technique referred to as Oracle Row-Level Security (RLS) or Fine Grained Access Control (FGAC), where security policies are attached to database objects themselves and parameterized using session parameters.
- Predicates are added to WHERE clause
Bob: SELECT * FROM Grades Oracle: SELECT * FROM Grades WHERE student = 'Bob'
See documentation for DMBS_RLS.ADD_POLICY when implementing policies.
Example of adding policy function
First create the policy function:
# For a static predicate: 'condition := 'grade="A+"';'
# Here we access the 'stu_name' parameter under the 'grade_app' namespace
CREATE FUNCTION check_grade(v_schema IN VARCHAR2, v_obj IN VARCHAR2)
RETURN VARCHAR2 AS condition VARCHAR2 (200);
BEGIN
condition := 'student = SYS_CONTEXT("grade_app", "stu_name")';
RETURN condition;
END check_grade;
Finally, we add a policy generated with the policy function.
BEGIN
DBMS_RLS.ADD_POLICY(
object_schema => 'CedricDB',
object_name => 'Grades',
policy_name => 'check_grade_policy',
policy_function => 'check_grade'
);
END;
Note that SYS_CONTEXT(ns, param, [length]) function is used to retrieve parameters in the Oracle environment. 'USERENV' is a built-in namespace, with the following parameters:
- SESSION_USER: Name of database user at logon
- SESSION_USERID: ID of database user at logon
- DB_NAME: Name of database
- ISDBA: Returns TRUE if user has authenticated with DBA privileges
Applying to the authorization-transparent context above, the policy function is now complete:
CREATE FUNCTION check_grade(v_schema IN VARCHAR2, v_obj IN VARCHAR2)
RETURN VARCHAR2 AS condition VARCHAR2 (200);
BEGIN
IF ( SYS_CONTEXT('USERENV', 'ISDBA') ) THEN
RETURN ' ';
ELSE
RETURN 'student = SYS_CONTEXT("grade_app", "stu_name")';
END IF;
END check_grade;
To extend the policy checking to UPDATE on top of the default SELECT, i.e. update own statistics, we can tweak the policy a little:
BEGIN
DBMS_RLS.ADD_POLICY(
object_schema => 'CedricDB',
object_name => 'Grades',
policy_name => 'check_grade_policy',
policy_function => 'check_grade',
update_check => TRUE
);
END;
Security policies can be applied to specific columns instead, so other non-sensitive columns can still be accessed by users (behavior can vary depending on policy when sensitive column is retrieved).
- Achieved by adding
sec_relevant_cols => 'grade' to theADD_POLICYprocedure. - Where only redaction with NULL is needed instead of hiding rows, add
sec_relevant_cols_opt => dbms_rls.ALL_ROWS. Note that redaction will not occur for primary keys (which cannot take NULL values).
Note also that policy predicates are applied with AND.
FGAC / VPD problems
Inconsistency between user's information goal and results can arise.
Alice: SELECT MIN(Salary) FROM Employee Database: SELECT MIN(Salary) FROM Employee WHERE Name = 'Alice'
Self-references / recursion is also not allowed, i.e. policy applied on table T cannot access table T.
CREATE FUNCTION check_grade(v_schema IN VARCHAR2, v_obj IN VARCHAR2)
RETURN VARCHAR2 AS condition VARCHAR2 (200);
BEGIN
SELECT 'grade = ' || MAX( grade ) into condition FROM Grades;
RETURN condition;
END check_grade;
Mandatory access control
Discretionary access controls (DAC) allow users to decide their own access policies, independent of consistency with global policies. Mandatory access controls (MAC) implements system-wide policies to provide tighter control over objects in the database. This prevents errant superusers from copying objects in the clear for users to access.
In the Multi-Level Security (MLS) model of MAC, three key concepts:
- Each object has a security level
- Each object may belong to some compartments
- A label consists of the security level and compartments, which can be assigned to both objects and subjects
Example of labels and access model
Given:
- object $$ O_1 $$ with label $$ L(O_1) $$ = (confidential, {})
- object $$ O_2 $$ with label $$ L(O_2) $$ = (confidential, {Asia, finance})
- subject $$ S $$ with label $$ L(S) $$ = (secret, {finance})
Access is granted if and only if $$ L(O) \subseteq{} L(S) $$, i.e. $$ S $$ can access $$ O_1 $$ but not $$ O_2 $$.
Bell and LaPadula [BLP73] proposed a formal mathematical model for MLS, proving that information cannot leak to subjects not cleared for it if the following two properties are ensured:
- No read up: $$ S $$ can read $$ O $$ iff $$ L(O) \subseteq L(S) $$
- No write down: $$ S $$ can write $$ O $$ if $$ L(S) \subseteq L(O) $$, i.e. subjects can write to scope not less narrower than own scope.
In the context of databases, we can apply access controls at different granularity:
- One label per table
- One label per tuple/row
- One label per value in each tuple: $$ R(A_1,A_2,...,A_d) $$ maps to $$ R'(A_1,C_1,A_2,C_2,...,A_d,C_d,TC) $$
- TC represents the highest security level among all attributes
Example of table visibility by lower level users
Since primary keys cannot be NULL, the entire row is hidden, while the total classification is reduced to the subject's level with appropriate redactions.

Issues easily pop up with multi-level relations, due to masked rows, e.g. user of lower classification attempts to add new row with existing primary key. Rather than denying insertions (leaks information about existence) or modify existing row (lower level can unilaterally corrupt data), we use poly-instantiation instead.
- Actual primary key is a combination of original primary key + TC level (or all C levels + TC as proposed in [SIGMOD91, p50-59])
- This allows insertion of rows with same primary key but at different classification levels.
Summary of rules
Results from selections:
- TC is downgraded to maximum of subject's and row's classification
- Redaction to NULL is always assumed
- All NULL redactions are set to Unclassified
Table of behaviours, for the case of (1) no polyinstantiation, (2) polyinstantiation with TC, (3) polyinstantiation with the whole classification tuple:
| No poly | TC only | All C | |
|---|---|---|---|
| Select regular field higher security | NULL | NULL | NULL |
| Select primary key higher security | Hidden | Lower/Hidden | Lower/Hidden |
| Insertion of lower security | - | Insert | Insert |
| Update of lower security | - | Insert | Insert |
| Deletion of lower security | - | NA | Delete |
Actually not a really good table, but a working one nonetheless.
Exercise for MAC

Answer: 3-4 problems.
Week 1
Module information
Learning objectives
- Overview of database security concepts and techniques
- New directions of database security
- Introductory coverage of databases
This is not a course on security of distributed databases (another module) and also will not cover basic database attacks (undergraduate modules).
Requirements
- Databases: Relational models, writing SQL queries, index structures (B-trees), query tree processing algorithms
- Cryptography: Public-key, hash, etc.
- Probabilistic analysis
{kind=link}
Grading
- 50% final exams
- 50% project
- Two sub-projects
- One research paper presentation (week 10-12 lectures)
- Groups (of up to five) to form by Week 4
References
Databases:
- Ramakrishnan & Gehrke: Database Management Systems
- Garcia-Molina, Ullman & Widom: Database Systems: The Complete Book
- Silberschatz, Korth & Sudarshan: Database System Concepts
Security:
- Pfleeger & Margulies: Security in Computing
- Stallings: Cryptography and Network Security
- Knox, Maroulis & Gaetjen: Oracle Database 12c Security
Additional research papers for each topic
How/What to secure
Databases can be secured using different techniques, each serving its own purpose.
- Access control
- Query auditing
- Data sanitization
- Query authentication
- Encrypted database
- Trusted hardware
Main set of requirements for database security techniques:
- Maintain confidentiality
- Whether information is disclosed only to authorized
- Maintain integrity
- Protect against accidental/malicious modifications
- Availability
- Ensure delivery of data/resource/service
- Accountability
- Trace actions to users
- Enumerate access lists
- Privacy
- Special type of confidentiality, for personal information, e.g. anonymization of personal identifiable information for research
Examples of attacks, which may not necessarily be an access compromise, but rather about preventing disclosure of database information that users should not have access to.
Example of inference attack

Given requirements that users cannot inquire about any individual student's grade, but can check grade statistics.
Answering all three queries can compromise Alice's grade. Statement 1 will yield A+C+D, statement 2 yields A+B+E+F, statement 3 will yield A+B+C+D+E+F => Alice's can be revealed via subtraction.
Access control
Purpose of access control is to ensure all direct accesses to database objects are authorized, via mapping of subjects (i.e. entities) to allowed actions (e.g. read, write). Requirements:
- Cannot be bypassed
- Access control must enforce organizational policies
- Must also enforce least-privilege restrictions
- i.e. minimum set of access rights required for current job + added when needed and discarded after use
Three types of access control: Mandatory access control (MAC), discretionary access control (DAC), role-based access control (RBAC).
Discretionary Access Control
Users can grant and revoke privileges to other users.
Almost all commercial systems support DAC. Current DAC models for relational databases are based on System R authorization model, where:
- Protect tables and views objects
- Provide privileges such as select, update, insert, etc.
Grant operation
Typical SQL statement can look like this:
GRANT (PrivilegeList|ALL PRIVILEGES) ON (Relation|View) TO (UserList|PUBLIC) [WITH GRANT OPTION]
Recall that specific views can also be granted, and the rights a user has is the union of all rights granted.
GRANT select(Name), insert ON Employee TO Jim GRANT select ON Employee TO Jim WITH GRANT OPTION # Jim can exercise select and insert privileges, but only grant select.
Revoke operation
General statement looks like this:
GRANT (PrivilegeList|ALL PRIVILEGES) ON (Relation|View) TO (UserList|PUBLIC)
The mechanism of revocation can be tricky to implement, e.g. should revocation be cascaded down to other users? Consider the cyclical grant privilege that will not disappear when Bob revokes Ann's privilege.

To solve this problem, we can formalize a recursive revocation algorithm, such that applying revocation $$R_i$$ on a sequence of grant operations $$ G_1 \cdots G_n $$ should yield an identical sequence $$ G_1 \cdots G_{i-1} G_{i+1} \cdots G_n$$. The brute-force method is to replay all the grant operations less the operation revoked.
Cascading revocation (System R)
System R assigns timestamps to grant operations, then revocation is recursively propagated by looking at timestamps of incoming and outgoing grant operations.

Revocation operation is potentially linear in size of graph (incurs overheads) as well as invalidate a large number of applications.
Non-cascading revocation
Alternative is to avoid cascading of revocations to prevent downstream applications from unexpectedly losing access, i.e. "being a responsible grandparent".

In example below, Ann adopts Sue after revoking Jim's grant privilege, as expected.

Note that Pat is conventionally also adopted by Ann as well - this prevents Ann from knowing whether Pat was orphaned by that revocation operation or not (otherwise different behavior if Cath does not grant Jim).
View/Content-based Authorization
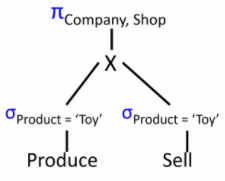
Access can be further restricted to individual views instead of the entire base table. This requires queries on views to be transformed into queries on base tables, e.g.
owner/> CREATE VIEW Sal AS SELECT * FROM Employee WHERE Salary < 20000;
owner/> GRANT select ON Sal TO Ann;
Ann/> SELECT * FROM Sal WHERE Job='Crew';
=== SELECT * FROM Employee WHERE Salary < 20000 AND Job='Crew';
This is in the realm of query processing, i.e.
- Query parsing
- Catalog lookup
- Authorization checking (against the view and not the base tables!)
- View composition
- Query optimization
Authorization granted to the view definer is then dependent on the authorization the definer has on the base table, as well as the view semantics (must map to possible operations).
Example
Suppose Bob owns the Employee table.
1. Bob has update privilege on both EmployeeNum and Salary on V1.
CREATE VIEW V1 (EmployeeNum, Salary) AS SELECT EmployeeNumber, Salary FROM Employee WHERE Job='Programmer';
2. Bob does not have update privilege on "Total_Sal", since update operation not defined.
CREATE VIEW V1 (EmployeeNum, Total_Sal) AS SELECT EmployeeNumber, Salary+Bonus FROM Employee WHERE Job='Programmer';
3. Tim has select and update privileges on V1, since privileges granted by Bob for base table.
Bob/> GRANT select, update ON Employee TO Tim;
Tim/> CREATE VIEW V1 (EmployeeNum, Annual_Sal) AS
SELECT EmployeeNum, Salary*12 FROM Employee;
Exercises on DAC










Answers: Top, Yes, No, Yes, No, Yes, Yes, No, Bad and BadLocal removed, Cath select and update Dave select.